NWAVE Tutorial 3: CPU/GPU Model Handling
This tutorial shows that NWAVE models run identically on CPU and GPU, and covers how to port between devices and quantify the throughput gains.
By the end of this tutorial you will have:
- Built portable
LIF,H1v1, andH1v2networks with explicitforward_cpu/forward_gpupaths - Verified numerical equivalence between CPU and GPU at matched weights
- Applied both porting patterns (generic
load_state_dictand in-placeto_gpu()) - Benchmarked inference and training speedup across model families and sequence lengths
import time
import random
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from nwavesdk.layers import (
LIFSynapse,
LIFLayer,
H1v1Synapse,
H1v1Layer,
H1v2Synapse,
H1v2Layer,
prepare_net,
)
def set_seed(seed=7):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
set_seed(7)
gpu_available = torch.cuda.is_available()
print(f"GPU available: {gpu_available}")
if gpu_available:
print(f"GPU name: {torch.cuda.get_device_name(0)}")
nwavesdk version: 1.0.0a0+cu
/opt/conda/envs/PyTorch/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
2026-04-28 10:15:32,683 INFO util.py:154 -- Missing packages: ['ipywidgets']. Run `pip install -U ipywidgets`, then restart the notebook server for rich notebook output.
2026-04-28 10:15:32,995 INFO util.py:154 -- Missing packages: ['ipywidgets']. Run `pip install -U ipywidgets`, then restart the notebook server for rich notebook output.
GPU available: True
GPU name: NVIDIA GeForce RTX 3050 6GB Laptop GPU
1. Build Portable Networks
Below we define three explicit network classes, one per model family:
LIFSNNH1SNNH1v2SNN
Each class exposes the same API:
forward_cpu(x)for timestep-loop executionforward_gpu(x)for sequence-parallel executionto_gpu()to move model to GPU
Externally, the model will behave as usually, but internally it dispatches to the defined forward function, that, in case of CPU it iterates in time over the data, while in GPU it does in one-shot (as ANN network's layers like convolution, linear and so on).
Why GPU Does Not Iterate Over Time
On CPU, the HW layer API computes one timestep at a time ([B, N]), so Python loops over T.
On GPU, kernels consume the full sequence tensor ([B, T, N]) and parallelize time/channel operations internally.
In the CPU forward, Python iterates over T timesteps and accumulates outputs. In the GPU forward, the kernel receives the full [B, T, N] tensor and parallelises time internally — no Python loop.
class LIFSNN(nn.Module):
def __init__(
self,
in_features,
hidden_features,
out_features,
dt=1e-3,
tau1=20e-3,
tau2=20e-3,
device: str = "cpu",
):
super().__init__()
if device not in {"cpu", "gpu"}:
raise ValueError(f"Unsupported device={device}")
self.cfg = {
"in_features": in_features,
"hidden_features": hidden_features,
"out_features": out_features,
"dt": dt,
"tau1": tau1,
"tau2": tau2,
}
self.device_flag = device
self.s1 = LIFSynapse(in_features, hidden_features, device=device)
self.l1 = LIFLayer(
n_neurons=hidden_features,
taus=tau1,
thresholds=1.0,
reset_mechanism="subtraction",
dt=dt,
layer_topology="FF",
device=device,
)
self.s2 = LIFSynapse(hidden_features, out_features, device=device)
self.l2 = LIFLayer(
n_neurons=out_features,
taus=tau2,
thresholds=1.0,
reset_mechanism="subtraction",
dt=dt,
layer_topology="FF",
device=device,
)
self.forward = self.forward_gpu if device == "gpu" else self.forward_cpu
def to_gpu(self):
for m in [self.s1, self.l1, self.s2, self.l2]:
m.to_gpu()
self.device_flag = "gpu"
self.forward = self.forward_gpu
return self
def forward_cpu(self, x):
prepare_net(self)
spk1, mem1, spk2, mem2 = [], [], [], []
for t in range(x.shape[1]):
q1 = self.s1(x[:, t, :])
s1, m1 = self.l1(q1)
q2 = self.s2(s1)
s2, m2 = self.l2(q2)
spk1.append(s1)
mem1.append(m1)
spk2.append(s2)
mem2.append(m2)
return {
"spikes": [torch.stack(spk1, dim=1), torch.stack(spk2, dim=1)],
"mem": [torch.stack(mem1, dim=1), torch.stack(mem2, dim=1)],
}
def forward_gpu(self, x):
if not torch.cuda.is_available():
raise RuntimeError("GPU backend requested, but CUDA is not available.")
prepare_net(self)
x = x.to("cuda", non_blocking=True).contiguous().to(torch.float32)
q1 = self.s1(x)
s1, m1 = self.l1(q1)
q2 = self.s2(s1)
s2, m2 = self.l2(q2)
return {
"spikes": [s1, s2],
"mem": [m1, m2],
}
The hardware-aware networks (H1SNN, H1v2SNN) follow the same device-dispatch pattern as LIFSNN. Only the layer classes and a few constructor arguments differ.
class H1SNN(nn.Module):
def __init__(
self,
in_features,
hidden_features,
out_features,
dt=1e-3,
tau1=20e-3,
tau2=20e-3,
device: str = "cpu",
):
super().__init__()
if device not in {"cpu", "gpu"}:
raise ValueError(f"Unsupported device={device}")
self.cfg = {
"in_features": in_features,
"hidden_features": hidden_features,
"out_features": out_features,
"dt": dt,
"tau1": tau1,
"tau2": tau2,
}
self.device_flag = device
self.s1 = H1v1Synapse(
in_features, hidden_features, device=device, lif_threshold=1.0
)
self.l1 = H1v1Layer(
n_neurons=hidden_features,
taus=torch.full((hidden_features,), tau1),
dt=dt,
layer_topology="FF",
device=device,
)
self.s2 = H1v1Synapse(
hidden_features, out_features, device=device, lif_threshold=1.0
)
self.l2 = H1v1Layer(
n_neurons=out_features,
taus=torch.full((out_features,), tau2),
dt=dt,
layer_topology="FF",
device=device,
)
self.forward = self.forward_gpu if device == "gpu" else self.forward_cpu
def to_gpu(self):
for m in [self.s1, self.l1, self.s2, self.l2]:
m.to_gpu()
self.device_flag = "gpu"
self.forward = self.forward_gpu
return self
def forward_cpu(self, x):
prepare_net(self)
spk1, mem1, spk2, mem2 = [], [], [], []
for t in range(x.shape[1]):
q1 = self.s1(x[:, t, :])
s1, m1 = self.l1(q1)
q2 = self.s2(s1)
s2, m2 = self.l2(q2)
spk1.append(s1)
mem1.append(m1)
spk2.append(s2)
mem2.append(m2)
return {
"spikes": [torch.stack(spk1, dim=1), torch.stack(spk2, dim=1)],
"mem": [torch.stack(mem1, dim=1), torch.stack(mem2, dim=1)],
}
def forward_gpu(self, x):
if not torch.cuda.is_available():
raise RuntimeError("GPU backend requested, but CUDA is not available.")
prepare_net(self)
x = x.to("cuda", non_blocking=True).contiguous().to(torch.float32)
q1 = self.s1(x)
s1, m1 = self.l1(q1)
q2 = self.s2(s1)
s2, m2 = self.l2(q2)
return {
"spikes": [s1, s2],
"mem": [m1, m2],
}
class H1v2SNN(nn.Module):
def __init__(
self,
in_features,
hidden_features,
out_features,
dt=1e-3,
tau1=20e-3,
tau2=20e-3,
device: str = "cpu",
):
super().__init__()
if device not in {"cpu", "gpu"}:
raise ValueError(f"Unsupported device={device}")
self.cfg = {
"in_features": in_features,
"hidden_features": hidden_features,
"out_features": out_features,
"dt": dt,
"tau1": tau1,
"tau2": tau2,
}
self.device_flag = device
self.s1 = H1v2Synapse(
in_features, hidden_features, device=device, lif_threshold=1.0
)
self.l1 = H1v2Layer(
n_neurons=hidden_features,
taus=torch.full((hidden_features,), tau1),
dt=dt,
layer_topology="FF",
device=device,
)
self.s2 = H1v2Synapse(
hidden_features, out_features, device=device, lif_threshold=1.0
)
self.l2 = H1v2Layer(
n_neurons=out_features,
taus=torch.full((out_features,), tau2),
dt=dt,
layer_topology="FF",
device=device,
)
self.forward = self.forward_gpu if device == "gpu" else self.forward_cpu
def to_gpu(self):
for m in [self.s1, self.l1, self.s2, self.l2]:
m.to_gpu()
self.device_flag = "gpu"
self.forward = self.forward_gpu
return self
def forward_cpu(self, x):
prepare_net(self)
spk1, mem1, spk2, mem2 = [], [], [], []
for t in range(x.shape[1]):
q1 = self.s1(x[:, t, :])
s1, m1 = self.l1(q1)
q2 = self.s2(s1)
s2, m2 = self.l2(q2)
spk1.append(s1)
mem1.append(m1)
spk2.append(s2)
mem2.append(m2)
return {
"spikes": [torch.stack(spk1, dim=1), torch.stack(spk2, dim=1)],
"mem": [torch.stack(mem1, dim=1), torch.stack(mem2, dim=1)],
}
def forward_gpu(self, x):
if not torch.cuda.is_available():
raise RuntimeError("GPU backend requested, but CUDA is not available.")
prepare_net(self)
x = x.to("cuda", non_blocking=True).contiguous().to(torch.float32)
q1 = self.s1(x)
s1, m1 = self.l1(q1)
q2 = self.s2(s1)
s2, m2 = self.l2(q2)
return {
"spikes": [s1, s2],
"mem": [m1, m2],
}
def make_cpu_model(family, in_features, hidden_features, out_features, dt):
family = family.lower()
if family == "lif":
return LIFSNN(in_features, hidden_features, out_features, dt=dt, device="cpu")
if family == "h1v1":
return H1SNN(in_features, hidden_features, out_features, dt=dt, device="cpu")
if family == "h1v2":
return H1v2SNN(in_features, hidden_features, out_features, dt=dt, device="cpu")
raise ValueError(f"Unsupported family={family}")
2. Workload Setup
We use synthetic spike sequences so the notebook is self-contained. Purpose of this notebook is to give an idea of how to use different devices for training and how to re-utilize models in different scenarios.
IN_FEATURES = 16
HIDDEN_FEATURES = 24
OUT_FEATURES = 8
DT = 1e-3
# Parity workload
B_PARITY = 32
T_PARITY = 64
# Benchmark workload
B_BENCH = 128
T_BENCH = 1000
set_seed(123)
x_parity = (torch.rand(B_PARITY, T_PARITY, IN_FEATURES) < 0.2).float()
x_bench = (torch.rand(B_BENCH, T_BENCH, IN_FEATURES) < 0.2).float()
print("x_parity shape:", tuple(x_parity.shape))
print("x_bench shape:", tuple(x_bench.shape))
x_parity shape: (32, 64, 16)
x_bench shape: (128, 1000, 16)
3. CPU/GPU Equivalence at Parity of Weights
For each family we are going to:
- Build the corresponding explicit CPU model (
LIFSNN,H1SNN,H1v2SNN) - Port to GPU preserving exact weights
- Run the same input sequence
- Compare outputs from final layer to assess that models are effectively doing same computations
So we build a function that does the forward of the two models (using the casting function to port to device), and then we will visually inspect the membranes of the layer to assess correctness.
@torch.no_grad()
def check_match(family, x):
set_seed(999)
model_cpu = make_cpu_model(
family=family,
in_features=IN_FEATURES,
hidden_features=HIDDEN_FEATURES,
out_features=OUT_FEATURES,
dt=DT,
)
out_cpu = model_cpu.forward(x)
model_gpu = model_cpu.to_gpu()
out_gpu = model_gpu.forward(x)
spk_cpu = out_cpu["spikes"][-1].detach().cpu()
spk_gpu = out_gpu["spikes"][-1].detach().cpu()
mem_cpu = out_cpu["mem"][-1].detach().cpu()
mem_gpu = out_gpu["mem"][-1].detach().cpu()
return {
"spk_cpu": spk_cpu,
"spk_gpu": spk_gpu,
"mem_cpu": mem_cpu,
"mem_gpu": mem_gpu,
}
3.1 Membrane Equivalence Plots
We add two visual checks for each family:
- Single neuron trace over time (CPU vs GPU)
- One batch element heatmap over all neurons and timesteps (CPU, GPU, absolute difference)
def plot_membrane_equivalence(
mem_cpu, mem_gpu, family_label, batch_idx=0, neuron_idx=0
):
# mem tensors: [B, T, N]
# Plot 1: one neuron over time for one batch element
t = np.arange(mem_cpu.shape[1])
cpu_trace = mem_cpu[batch_idx, :, neuron_idx].numpy()
gpu_trace = mem_gpu[batch_idx, :, neuron_idx].numpy()
plt.figure(figsize=(8, 3.5))
plt.plot(t, cpu_trace, "--", linewidth=2, label="CPU", alpha=0.7)
plt.plot(t, gpu_trace, "-", linewidth=1.8, label="GPU", alpha=0.4)
plt.title(
f"{family_label}: Membrane trace | batch={batch_idx}, neuron={neuron_idx}"
)
plt.xlabel("Timestep")
plt.ylabel("Membrane")
plt.grid(alpha=0.25)
plt.legend()
plt.tight_layout()
plt.show()
if not gpu_available:
print("GPU not available: skipping membrane equivalence plots.")
else:
batch_idx = 0
neuron_idx = 0
for family in ["lif", "h1v1", "h1v2"]:
net_res = check_match(family, x_parity)
plot_membrane_equivalence(
mem_cpu=net_res["mem_cpu"],
mem_gpu=net_res["mem_gpu"],
family_label=family.upper(),
batch_idx=batch_idx,
neuron_idx=neuron_idx,
)
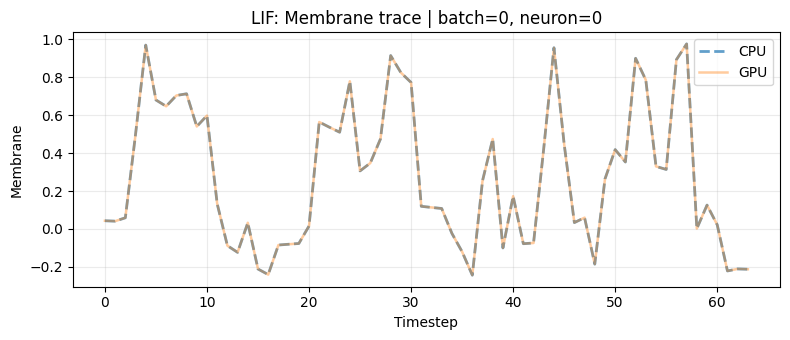
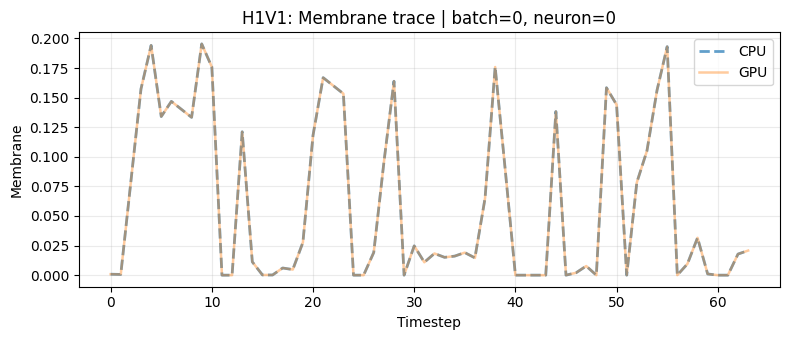
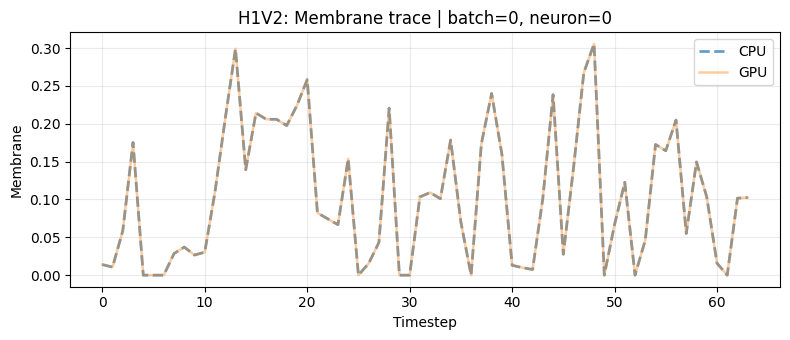
4. Porting Patterns Between Devices
A. Generic pattern for all families (always valid)
- instantiate the destination model class
load_state_dict(...)
B. In-place convenience pattern
For all NWAVE modules, to_gpu() exists on layer/synapse modules and can be used through to_gpu().
if gpu_available:
# Generic pattern (works for LIF, H1v1, H1v2)
set_seed(321)
cpu_generic = H1v2SNN(
IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT, device="cpu"
)
gpu_generic = H1v2SNN(
IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT, device="gpu"
)
gpu_generic.load_state_dict(cpu_generic.state_dict(), strict=True)
set_seed(321)
cpu_h1 = H1SNN(IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT, device="cpu")
cpu_h1.to_gpu()
print(
"Generic state_dict porting and H1v1/H1v2 to_gpu porting examples created successfully."
)
else:
print("GPU not available: device-porting demo skipped.")
Generic state_dict porting and H1v1/H1v2 to_gpu porting examples created successfully.
5. IMPORTANT: Deep vs "Shallow" Copy When Calling to_gpu()
What cpu_model.to_gpu() does
- It mutates the same model object in place.
- Returned object is the same instance (
returned is cpu_modelisTrue). - All references to that model now see GPU modules.
What copy.deepcopy(cpu_model).to_gpu() does
deepcopy(...)creates a new independent model object with copied parameters.to_gpu()then moves only that new copy to GPU.- Original
cpu_modelstays on CPU.
Practical impact
- Use
cpu_model.to_gpu()when you do not need the CPU model anymore. - Use
copy.deepcopy(cpu_model).to_gpu()when you need CPU and GPU models alive at the same time (fair benchmark, side-by-side debug, A/B checks).
import copy
if gpu_available:
cpu_base = H1SNN(IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT, device="cpu")
# In-place move: same object, now on GPU.
same_ref = cpu_base
moved = cpu_base.to_gpu()
print("In-place:")
print(" moved is cpu_base:", moved is cpu_base)
print(" same_ref is cpu_base:", same_ref is cpu_base)
print(" cpu_base device flag:", cpu_base.device_flag)
# Deep copy + move: independent objects.
cpu_base2 = H1SNN(IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT, device="cpu")
gpu_copy = copy.deepcopy(cpu_base2).to_gpu()
print("Deep copy + move:")
print(" gpu_copy is cpu_base2:", gpu_copy is cpu_base2)
print(" cpu_base2 device flag:", cpu_base2.device_flag)
print(" gpu_copy device flag:", gpu_copy.device_flag)
else:
print("GPU not available: deep vs shallow demo skipped.")
In-place:
moved is cpu_base: True
same_ref is cpu_base: True
cpu_base device flag: gpu
Deep copy + move:
gpu_copy is cpu_base2: False
cpu_base2 device flag: cpu
gpu_copy device flag: gpu
Both variables now reference GPU modules because to_gpu() mutates the original object in place. Use copy.deepcopy first if the CPU model must remain alive.
6. Inference Benchmark (CPU vs GPU)
Same architecture, same weights, same input batch — timed separately on CPU and GPU.
- GPU warmup applied before timing to exclude kernel compilation overhead.
- Metric: average milliseconds per forward pass.
@torch.no_grad()
def benchmark_inference_ms(model, x, backend: str, warmup=10, runs=30):
backend = backend.lower()
if backend not in {"cpu", "gpu"}:
raise ValueError(backend)
model.eval()
for _ in range(warmup):
if backend == "cpu":
_ = model.forward_cpu(x)
else:
_ = model.forward_gpu(x.to("cuda"))
if backend == "gpu":
torch.cuda.synchronize()
t0 = time.perf_counter()
for _ in range(runs):
if backend == "cpu":
_ = model.forward_cpu(x)
else:
_ = model.forward_gpu(x)
if backend == "gpu":
torch.cuda.synchronize()
return (time.perf_counter() - t0) * 1000.0 / runs
if not gpu_available:
print("GPU not available: skipping inference speedup benchmark.")
else:
infer_rows = []
for i, family in enumerate(["lif", "h1v1", "h1v2"]):
set_seed(1000 + i)
cpu_model = make_cpu_model(
family, IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT
)
cpu_ms = benchmark_inference_ms(
cpu_model, x_bench, backend="cpu", warmup=5, runs=20
)
gpu_model = cpu_model.to_gpu()
gpu_ms = benchmark_inference_ms(
gpu_model, x_bench, backend="gpu", warmup=10, runs=20
)
infer_rows.append(
{
"family": family.upper(),
"cpu_ms": cpu_ms,
"gpu_ms": gpu_ms,
"speedup_x": cpu_ms / gpu_ms,
}
)
print()
print("Inference benchmark (avg ms/forward):")
for row in infer_rows:
print(
f"{row['family']:>3} | "
f"CPU={row['cpu_ms']:.3f} ms | "
f"GPU={row['gpu_ms']:.3f} ms | "
f"speedup={row['speedup_x']:.2f}x"
)
# Plot speedup bars
families = [r["family"] for r in infer_rows]
speedups = [r["speedup_x"] for r in infer_rows]
bars = plt.bar(families, speedups)
plt.title("Inference speedup (CPU time / GPU time)")
plt.xlabel("Model family")
plt.ylabel("Speedup")
plt.grid(axis="y", alpha=0.25)
for b, val in zip(bars, speedups):
plt.text(
b.get_x() + b.get_width() / 2.0,
val,
f"{val:.2f}x",
ha="center",
va="bottom",
)
plt.tight_layout()
plt.show()
Inference benchmark (avg ms/forward):
LIF | CPU=118.944 ms | GPU=2.451 ms | speedup=48.53x
H1V1 | CPU=152.186 ms | GPU=2.446 ms | speedup=62.23x
H1V2 | CPU=174.899 ms | GPU=2.647 ms | speedup=66.08x
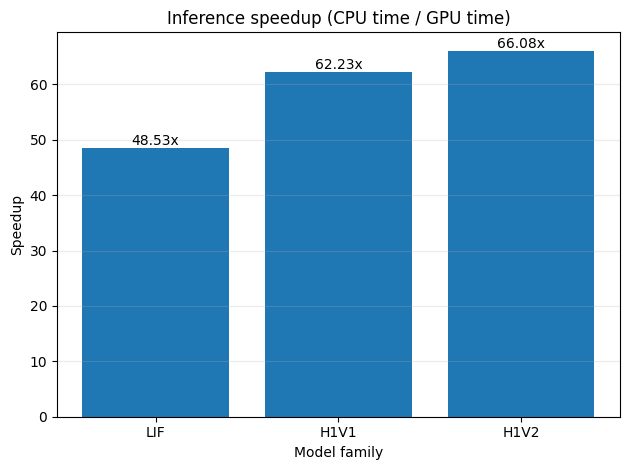
7. Training Throughput Benchmark
A short training workload to measure per-step throughput on CPU vs GPU.
- Same initialization and same batch order for a fair comparison.
- GPU warmup applied before timed steps.
def random_data(
total_steps, batch_size, timesteps, in_features, n_classes, p_spike=0.2, seed=77
):
g = torch.Generator().manual_seed(seed)
batches = []
for _ in range(total_steps):
x = (
torch.rand(batch_size, timesteps, in_features, generator=g) < p_spike
).float()
y = torch.randint(0, n_classes, (batch_size,), generator=g)
batches.append((x, y))
return batches
def train_one_step(model, backend: str, optimizer, x, y):
optimizer.zero_grad(set_to_none=True)
if backend == "cpu":
out = model.forward_cpu(x)
target = y
else:
out = model.forward_gpu(x)
target = y.to("cuda", non_blocking=True)
# Readout on final layer membrane
logits = out["mem"][-1].mean(dim=1)
loss = F.cross_entropy(logits, target)
loss.backward()
optimizer.step()
return float(loss.detach().cpu().item())
def get_time(
model,
backend: str,
batches,
lr=1e-3,
warmup_steps=4,
):
backend = backend.lower()
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# Warmup (important for GPU kernels and caches)
for i in range(warmup_steps):
x, y = batches[i]
_ = train_one_step(model, backend, optimizer, x, y)
if backend == "gpu":
torch.cuda.synchronize()
losses = []
t0 = time.perf_counter()
for x, y in batches[warmup_steps:]:
losses.append(train_one_step(model, backend, optimizer, x, y))
if backend == "gpu":
torch.cuda.synchronize()
elapsed = time.perf_counter() - t0
ms_per_step = 1000.0 * elapsed / len(losses)
mean_loss = float(np.mean(losses))
return ms_per_step, mean_loss
NUM_EPOCHS = 2
STEPS_PER_EPOCH = 6
WARMUP_STEPS = 4
TOTAL_STEPS = NUM_EPOCHS * STEPS_PER_EPOCH + WARMUP_STEPS
train_data = random_data(
total_steps=TOTAL_STEPS,
batch_size=96,
timesteps=80,
in_features=IN_FEATURES,
n_classes=OUT_FEATURES,
p_spike=0.2,
seed=2026,
)
if not gpu_available:
print("GPU not available: skipping fake training speedup benchmark.")
else:
train_rows = []
for i, family in enumerate(["lif", "h1v1", "h1v2"]):
set_seed(2000 + i)
cpu_model = make_cpu_model(
family, IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT
)
gpu_model = copy.deepcopy(cpu_model).to_gpu()
cpu_ms, cpu_loss = get_time(
cpu_model,
backend="cpu",
batches=train_data,
lr=1e-3,
warmup_steps=WARMUP_STEPS,
)
gpu_ms, gpu_loss = get_time(
gpu_model,
backend="gpu",
batches=train_data,
lr=1e-3,
warmup_steps=WARMUP_STEPS,
)
train_rows.append(
{
"family": family.upper(),
"cpu_ms": cpu_ms,
"gpu_ms": gpu_ms,
"speedup_x": cpu_ms / gpu_ms,
"cpu_loss": cpu_loss,
"gpu_loss": gpu_loss,
}
)
print()
print("Fake training benchmark (avg ms/step):")
for row in train_rows:
print(
f"{row['family']:>3} | "
f"CPU={row['cpu_ms']:.3f} ms | "
f"GPU={row['gpu_ms']:.3f} ms | "
f"speedup={row['speedup_x']:.2f}x | "
f"mean_loss(cpu/gpu)=({row['cpu_loss']:.4f}/{row['gpu_loss']:.4f})"
)
# Plot speedup bars
families = [r["family"] for r in train_rows]
speedups = [r["speedup_x"] for r in train_rows]
bars = plt.bar(families, speedups)
plt.axhline(1.0, linestyle="--", linewidth=1, color="black")
plt.title("Fake training speedup (CPU time / GPU time)")
plt.xlabel("Model family")
plt.ylabel("Speedup (x)")
plt.grid(axis="y", alpha=0.25)
for b, val in zip(bars, speedups):
plt.text(
b.get_x() + b.get_width() / 2.0,
val,
f"{val:.2f}x",
ha="center",
va="bottom",
)
plt.tight_layout()
plt.show()
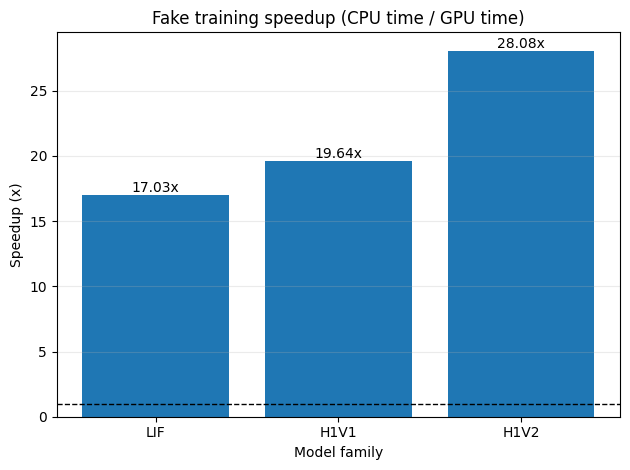
Fake training benchmark (avg ms/step):
LIF | CPU=15.289 ms | GPU=0.898 ms | speedup=17.03x | mean_loss(cpu/gpu)=(2.8495/2.8497)
H1V1 | CPU=27.783 ms | GPU=1.415 ms | speedup=19.64x | mean_loss(cpu/gpu)=(2.0796/2.0796)
H1V2 | CPU=29.720 ms | GPU=1.058 ms | speedup=28.08x | mean_loss(cpu/gpu)=(2.0793/2.0793)
7.1 Speedup vs Sequence Length
To understand how portability behaves as sequence time grows, we sweep timesteps:
[100, 500, 1000, 2000, 5000, 10000].
For each model family (LIF, H1v1, H1v2), we measure CPU and GPU inference time and plot
speedup as CPU_time / GPU_time versus timesteps.
TIMESTEP_SWEEP = [100, 500, 1000, 2000, 5000, 10000]
B_SWEEP = 32
P_SPIKE_SWEEP = 0.2
if not gpu_available:
print("GPU not available: skipping timestep sweep benchmark.")
else:
sweep_results = {}
for i, family in enumerate(["lif", "h1v1", "h1v2"]):
set_seed(5000 + i)
cpu_model = make_cpu_model(
family, IN_FEATURES, HIDDEN_FEATURES, OUT_FEATURES, dt=DT
)
gpu_model = copy.deepcopy(cpu_model).to_gpu()
rows = []
print(f"\n{family.upper()} | speedup vs timesteps")
for T in TIMESTEP_SWEEP:
set_seed(8000 + i * 100 + T)
x_t = (torch.rand(B_SWEEP, T, IN_FEATURES) < P_SPIKE_SWEEP).float()
if T <= 500:
warmup, runs = 4, 12
elif T <= 2000:
warmup, runs = 3, 8
else:
warmup, runs = 2, 4
cpu_ms = benchmark_inference_ms(
cpu_model, x_t, backend="cpu", warmup=warmup, runs=runs
)
gpu_ms = benchmark_inference_ms(
gpu_model, x_t, backend="gpu", warmup=warmup, runs=runs
)
speedup = cpu_ms / gpu_ms
rows.append(
{
"timesteps": T,
"cpu_ms": cpu_ms,
"gpu_ms": gpu_ms,
"speedup_x": speedup,
}
)
print(
f"T={T:>5} | CPU={cpu_ms:>9.3f} ms | GPU={gpu_ms:>9.3f} ms | speedup={speedup:>6.2f}x"
)
sweep_results[family] = rows
plt.figure(figsize=(8.5, 4.8))
for family in ["lif", "h1v1", "h1v2"]:
t_values = [r["timesteps"] for r in sweep_results[family]]
s_values = [r["speedup_x"] for r in sweep_results[family]]
plt.plot(t_values, s_values, marker="o", linewidth=2, label=family.upper())
plt.xscale("log")
plt.xlabel("Timesteps (log scale)")
plt.ylabel("Speedup = CPU time / GPU time")
plt.title("Speedup vs sequence length")
plt.grid(alpha=0.25, which="both")
plt.legend()
plt.tight_layout()
plt.show()
LIF | speedup vs timesteps
T= 100 | CPU= 6.203 ms | GPU= 0.150 ms | speedup= 41.30x
T= 500 | CPU= 39.981 ms | GPU= 0.689 ms | speedup= 58.01x
T= 1000 | CPU= 71.052 ms | GPU= 1.409 ms | speedup= 50.42x
T= 2000 | CPU= 139.865 ms | GPU= 2.685 ms | speedup= 52.08x
T= 5000 | CPU= 354.698 ms | GPU= 6.623 ms | speedup= 53.56x
T=10000 | CPU= 798.044 ms | GPU= 14.377 ms | speedup= 55.51x
H1V1 | speedup vs timesteps
T= 100 | CPU= 9.058 ms | GPU= 0.193 ms | speedup= 47.00x
T= 500 | CPU= 52.948 ms | GPU= 0.711 ms | speedup= 74.42x
T= 1000 | CPU= 101.285 ms | GPU= 1.400 ms | speedup= 72.35x
T= 2000 | CPU= 211.281 ms | GPU= 2.752 ms | speedup= 76.77x
T= 5000 | CPU= 516.715 ms | GPU= 6.776 ms | speedup= 76.26x
T=10000 | CPU= 1151.736 ms | GPU= 15.513 ms | speedup= 74.24x
H1V2 | speedup vs timesteps
T= 100 | CPU= 10.019 ms | GPU= 0.229 ms | speedup= 43.76x
T= 500 | CPU= 51.663 ms | GPU= 0.832 ms | speedup= 62.07x
T= 1000 | CPU= 100.691 ms | GPU= 1.550 ms | speedup= 64.96x
T= 2000 | CPU= 205.113 ms | GPU= 2.949 ms | speedup= 69.54x
T= 5000 | CPU= 589.459 ms | GPU= 7.497 ms | speedup= 78.63x
T=10000 | CPU= 1136.515 ms | GPU= 14.278 ms | speedup= 79.60x
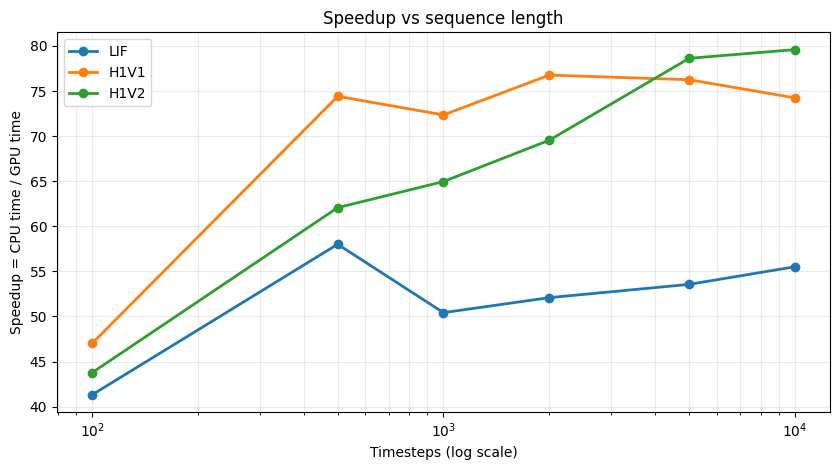
Longer sequences better approximate the continuous-time dynamics of the analog hardware. GPU throughput makes finer time discretisations practical without a proportional increase in wall-clock training time.
8. Practical Recommendation
| Scenario | Recommended device | Rationale |
|---|---|---|
| Early prototyping / debugging | CPU | Easier to inspect timestep states; no warmup overhead |
| Short sequences (T < 200) | CPU | GPU kernel launch overhead can exceed compute savings |
| Batch inference (T ≥ 500) | GPU | Kernel parallelism over time yields substantial speedup |
| Full training runs | GPU | Per-step throughput gains compound across epochs |
| Deployment validation | CPU | Final accuracy check before hardware export |